
In the fast-evolving world of artificial intelligence, deploying AI models on edge devices presents unique challenges. Edge AI systems are integral to applications requiring real-time data processing, such as autonomous vehicles, smart devices, and IoT sensors. However, these systems often operate under constraints related to memory, power, and computational resources. One innovative approach to addressing these challenges is model pruning, a technique that can significantly enhance the performance of AI models on edge devices.
Model pruning involves selectively removing parts of a neural network that are deemed non-essential. By doing so, the model's size and complexity are reduced without significantly affecting its predictive performance. This process not only lightens the computational load but also speeds up inference times, making it an invaluable strategy for edge AI systems. As we delve into the intricacies of model pruning, you'll discover how it can optimize AI systems for efficiency and effectiveness.
At its core, model pruning is a technique used to reduce the complexity of neural networks by eliminating redundant or less important parameters. In essence, it involves cutting away parts of the network that contribute little to the overall task performance. This process can lead to a more efficient model that requires fewer computational resources, which is particularly beneficial for edge devices with limited capabilities. Pruning removes unnecessary data to enhance model performance. The goal is to maintain the model's accuracy while reducing its size. This reduction is crucial for deploying models in environments where memory and power are constrained, such as in edge computing.
Model pruning addresses the constraints of edge devices by creating lightweight models that can function effectively within limited resource environments. By reducing the model's size, pruning decreases the amount of memory required, which is crucial for devices with restricted storage capacities. Additionally, smaller models tend to consume less power, prolonging battery life in portable edge devices.
Furthermore, model pruning can significantly enhance the speed of inference, which is critical for real-time applications. For instance, in autonomous vehicles, rapid decision-making is vital, and delays could lead to catastrophic outcomes. By employing pruned models, we can ensure faster processing times, thereby improving the device's responsiveness and overall performance. Embien's edge computing services combine hardware-aware pruning pipelines with deployment strategies tailored to specific embedded platforms, ensuring that pruned models map efficiently onto target processors with minimal latency.
Model Pruning in Edge AI Systems
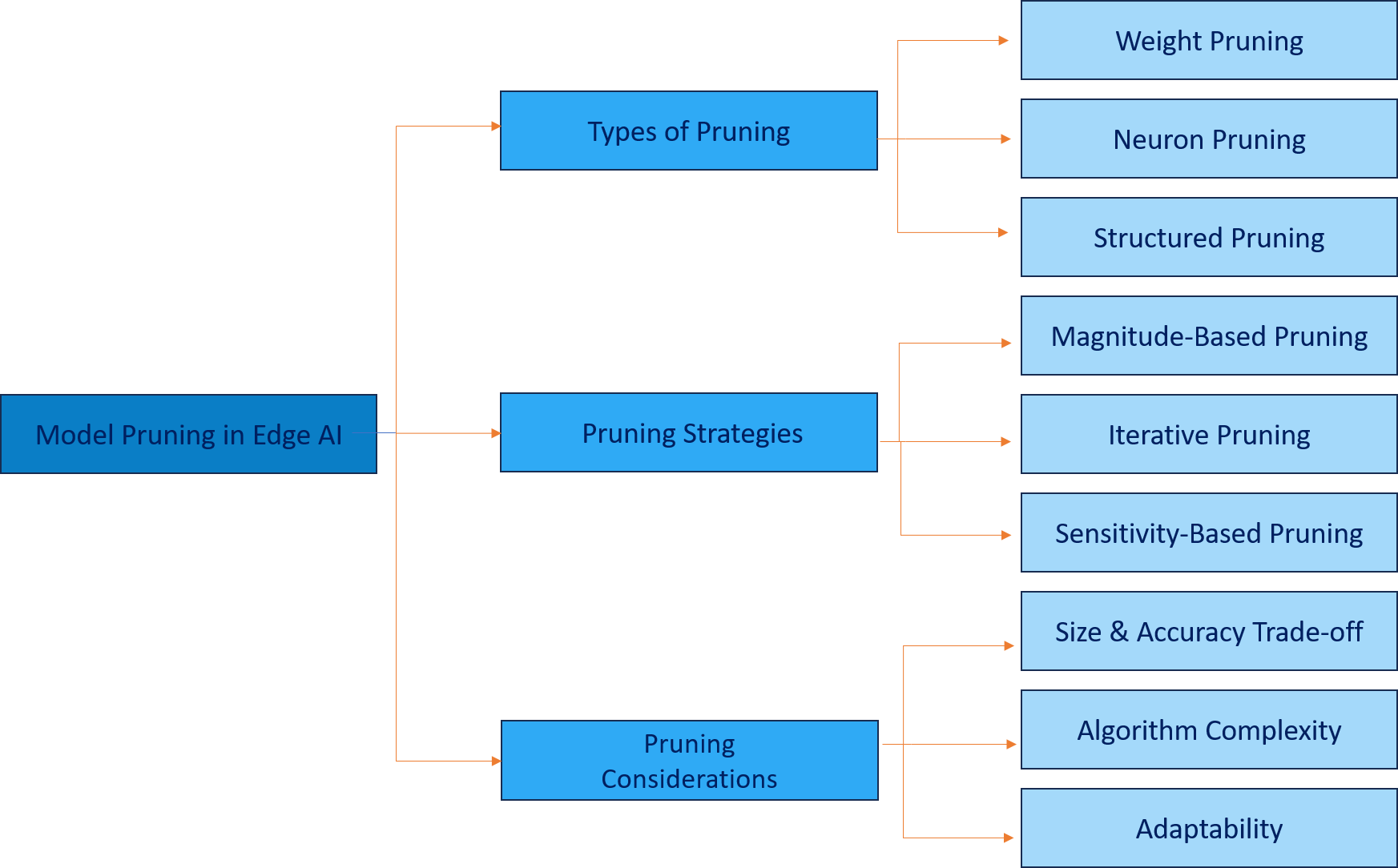
Model pruning in edge AI relies on several distinct types of pruning, each with its own approach and benefits. Understanding these types of pruning is crucial for selecting the appropriate method for a given application, especially in the context of edge AI systems.
Weight pruning focuses on removing individual weights from the neural network. This type of pruning is granular and precise, allowing for fine-tuning of the model. By eliminating weights that have minimal impact on the output, weight pruning achieves a more compact model. This method is particularly useful when aiming to reduce the model's footprint without sacrificing accuracy.
Neuron pruning involves removing entire neurons or nodes from the network. This approach simplifies the architecture by eliminating redundant neurons, which can lead to a significant reduction in the model's size. Neuron pruning is beneficial when the goal is to streamline the network's structure and improve computational efficiency.
Structured pruning targets entire structures within the network, such as filters or layers. By removing these larger components, structured pruning can lead to substantial reductions in model complexity. This method is effective when a more aggressive reduction in model size is required, making it ideal for severely resource-constrained environments.
Each of these types of pruning offers unique advantages and can be combined to achieve optimal results. The choice among pruning types should align with the specific performance goals and constraints of the edge AI system in question.
After selecting the appropriate pruning type, implementing the right pruning strategies for edge AI is crucial to maximizing the benefits of model pruning in edge AI systems. There are several commonly used pruning strategies for edge AI that can be tailored to the requirements of specific applications. Embien’s Digital Transformation Services help organizations deploy optimized Edge AI solutions that improve efficiency, scalability, and operational intelligence.
Magnitude-based pruning is a straightforward approach that removes weights based on their absolute values. Weights with smaller magnitudes are considered less significant and are pruned away. This method is simple to implement and can quickly yield substantial reductions in model size, making it a popular choice for edge AI systems.
Iterative pruning involves gradually removing weights or neurons over multiple training cycles. This strategy allows for continuous fine-tuning of the model, ensuring that performance is maintained even as complexity is reduced. Iterative pruning is particularly useful when maintaining accuracy is a priority.
Sensitivity-based pruning evaluates the impact of removing specific parameters on the model's overall performance. By identifying and pruning parameters that have minimal effect on accuracy, this strategy ensures that the model remains robust while reducing complexity. Sensitivity-based pruning requires more sophisticated analysis but can yield highly efficient models.
These strategies can be implemented individually or in combination to suit the unique demands of edge AI applications. By selecting the right strategy, we can create models that are both lightweight and capable. Once a pruned model is ready, Embien's application development services deliver the runtime software layer that integrates optimised model weights into production-ready inference applications on constrained edge platforms.
While model pruning offers numerous benefits, there are several considerations to keep in mind when implementing these techniques in edge AI systems.
One of the primary challenges in model pruning is maintaining a balance between reducing model size and preserving accuracy. Aggressive pruning can lead to a significant drop in performance, which may not be acceptable for certain applications.Embien’s AI & ML development services enable optimized AI models that balance accuracy, efficiency, and edge deployment performance.
The complexity of the pruning algorithm itself can be a limiting factor. Some advanced pruning techniques require substantial computational resources, which may not be feasible for edge devices.
The adaptability of pruned models to different tasks and environments is another critical consideration. Pruned models may need to be retrained or fine-tuned when deployed in new scenarios. Additionally, transferability across different hardware platforms should be evaluated to ensure consistent performance.
By addressing these considerations, we can effectively implement model pruning techniques that enhance the performance of edge AI systems without compromising their functionality.
Model Pruning in Edge AI is a proven approach for AI Model Optimization — selectively eliminating redundant network weights and structures so that models operate within the strict memory, power, and compute budgets of edge devices. Whether applying weight, neuron, or structured pruning strategies, the goal is always to match the pruning depth to the application's accuracy requirements and target hardware. Beyond pruning itself, embedded system optimization is equally critical: mapping a pruned network efficiently onto a real processor requires careful attention to memory layout, cache behaviour, and instruction throughput to fully realise the latency and power savings that pruning makes possible.

Learn how Embien's edge computing services apply model pruning strategies — weight, neuron, and structured pruning — to shrink AI models for deployment on memory-constrained microcontrollers and SoCs.

Explore Embien's application development services that wrap pruned edge AI models in optimised runtime software — ensuring fast, reliable inference within the power and memory limits of embedded systems.

A case study demonstrating pruned ML model deployment for real-time anomaly detection in wind turbine systems — showing how model pruning in edge AI enables low-latency predictive maintenance at the edge.